Neznana količina, ki jo merimo, je \( x
\). Imamo dva seta meritev, oba porazdeljena po normalni
porazdelitvi
\[ z_1 \sim N (x, \sigma_1 ^2 ) \quad
\text{ in } \quad z_2 \sim N(x, \sigma_2 ^2)
\]
Note
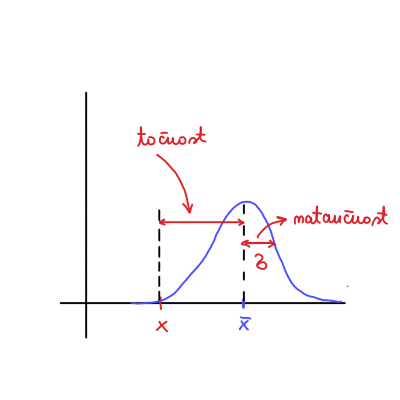
O točnosti in natančnosti: Razdalja med pričakovana vrednostjo \( x \) in njeno povprečno vrednostjo \( \bar{x} \) je točnost, medtem ko
odstopanje od povprečne vrednosti pa je natančnost.
Velika netočnost je ponavadi rezultat sistematska napaka.
Predpostavimo, da so naši izmerki natančni.
Naša seta meritev napišemo kot vsoto pričakovane vrednosti in šuma,
ki sta oba razporejena po normalni porazdelitvi.
\[ z_1 = x + r_1; \quad r_1 \sim N (0,
\sigma_1 ^2) \quad \text{ in } \quad z_2 = x + r_2; \quad r_2 \sim N(0,
\sigma_2 ^2)
\]
Člen \( \left\langle r_1 w \right\rangle
\) je kovarianca in ker je \( r_2 = r_2
(r_1, w) \) in sta \( r_1 \) in
\( w \) neodvisni, je njuna kovarianca
ničelna.
V primeru \( i = j \) dobimo \( \sigma_i ^2 = \left\langle (\bar{x}_i - x_i) ^2
\right\rangle = \sigma_i ^2 \), kar je že zapis variance znotraj
zapisa za kovarianco!
diagonalni elementi kovariantne matriko \(
\left( M \right)_{ii} = \sigma_{ii} = \sigma_i ^2 \) so
variance
izvendiagonalni elementi so kovariance \(
\left( M \right)_{ij, i \ne j} = \sigma_{ij} \)
Za vektor \( \mathbf{u} = \left( f_1
(\mathbf{x}), f_2 (\mathbf{x}), \ldots, f_n (\mathbf{x}) \right)
\) nas zanima ocena \( \bar{\mathbf{u}}
\), zato da lahko izračunamo kovariantno matriko \( U \).
Upoštevali smo, da velja \( \left\langle
J_{\mathbf{u}} (\bar{\mathbf{x}})\right\rangle =
J_{\mathbf{u}}(\bar{\mathbf{x}}) \), saj je to matrika konstant.
Spomnimo se še definicije Jacobijeve matrike, ki je
Imamo delec, ki se premika s hitrostjo \( v
\). Imamo dva senzorja, ki se nahajata na koordinatah \( x_1 \) in \( x_2
\). Čas za prelet intervala je \(
\Delta t \). Senzor 1 ima oceno meritev \( \bar{x}_1 \) in nedoločenost \( \sigma_1 \). Senzor 2 ima oceno meritve
\( \bar{x}_2 \) in nedoločenost \( \sigma_2 \). Senzorja sta neodvisna.
Izmerjeni oceni želimo združiti v novo oceno za \( x \), ki jo označimo z \( \tilde{x} \). Zanjo zahtevamo, da je \( \left\langle \tilde{x} \right\rangle = x
\) (pričakovana vrednost nove ocene je še zmeraj \( x \)). Zapišemo
\[ \tilde{x} = x + \tilde{r}.
\]
Novo oceno zapišemo z nastavkom linearne kombinacije ocen
\[ \tilde{x} = a z_1 + b z_2.
\]
Zahtevamo linearno kombinacijo, saj samo \(
z_1 \) ne bi zadostil pogoju \(
\left\langle \tilde{x} \right\rangle = x \).
Razpišemo vse količine
\[\begin{align*}
\tilde{x} = x + \tilde{r} &= a \left( x + r_1 \right) + b (x +
r_2) \\
x + \tilde{r} &= x (a + b) + ar_1 + b_2 && \left/
\left\langle \cdot \right\rangle \right. \\
x &= x (a + b),
\end{align*}
\]
kjer dobimo pogoj \( a + b = 1 \)
oz. \( a = 1 - b \).
Novo oceno torej lahko zapišemo kot
\[ \tilde{x} = (1 - b) z_1 + z_2 = z_1 + b
(z_2 - z_1).
\]
Členu \( (z_2 - z_1) \) pravimo
inovacija, \( b \) pa pravimo
utež/faktor. Člen se imenuje inovacija, saj \(
z_1 \) nenehno z večanjem meritev popravlja drugi člen.
V primeru vrednosti \( b = \frac{1}{2}
\) dobimo ravno povprečje
kar pomeni, da je povprečje dobra, vendar ne optimalna ocena.
Iščemo \( b_0 \) - optimalno utež -
ki nam poda optimalno oceno (optimalno združevanje \( z_1 \) in \( z_2
\)).
Beseda optimalno pomeni, da je napaka minimalna. Optimalno oceno bomo
označili z \( \tilde{x} = \hat{x} \). Z
drugimi besedami zapisan pogoj za optimalno oceno je, da zahtevamo
najmanjšo varianco.
V primeru, ko imamo negotovosti, ki so enake, lahko merimo.
V kontekstu fizikalnega praktkuma: meritve so bile opravljene na isti
napravi v obdobju kratkega časa in zato se lahko predpostavi enakost
negotovosti posameznih meritev. Povprečenje naših rezultatov torej sploh
ni bilo tako napačno.
Če v \(\ref{ali:vari}\) vstavimo
vrednost \( b_0 \) za optimalno oceno,
lahko izračunamo kakšna je negotovost optimalne ocene
Namesto računanja bomo najprej izostavili \( \sigma_2 ^2 - \sigma_{12} \) in \( \sigma_1 ^2 - \sigma_{12} \), kjer zadnji
člen s faktorjem \( 2 \) razbijemo na
dva delo (dobesedno \( 2x = x + x \)).
Dobimo
V prvi vrstici se po računanju oklepajev pokrajša v prvi faktor v
drugi vrstici, ki smo ga lahko izpostavili. Drugi faktor druge vrstice
pa je ravno imenovalec \( I \).